In this post, we present Koala, a chatbot trained by fine-tuning Meta’s LLaMA on discussion information collected from the web. We explain the dataset curation and training procedure of our design, and likewise provide the outcomes of a user research study that compares our design to ChatGPT and Stanford’s Alpaca Our outcomes reveal that Koala can successfully react to a range of user inquiries, producing reactions that are frequently chosen over Alpaca, and a minimum of connected with ChatGPT in over half of the cases.
We hope that these outcomes contribute even more to the discourse around the relative efficiency of big closed-source designs to smaller sized public designs. In specific, it recommends that designs that are little adequate to be run in your area can catch much of the efficiency of their bigger cousins if trained on thoroughly sourced information. This may suggest, for instance, that the neighborhood must put more effort into curating premium datasets, as this may do more to make it possible for more secure, more accurate, and more capable designs than merely increasing the size of existing systems. We stress that Koala is a research study model, and while we hope that its release will offer an important neighborhood resource, it still has significant imperfections in regards to material, security, and dependability, and must not be utilized beyond research study.
System Summary
Big language designs (LLMs) have actually allowed significantly effective virtual assistants and chat bots, with systems such as ChatGPT, Bard, Bing Chat, and Claude able to react to a breadth of user inquiries, offer sample code, and even compose poetry. A lot of the most capable LLMs need big computational resources to train, and frequently utilize big and exclusive datasets. This recommends that in the future, extremely capable LLMs will be mostly managed by a little number of companies, and both users and scientists will pay to engage with these designs without direct access to customize and enhance them by themselves. On the other hand, current months have actually likewise seen the release of significantly capable easily offered or (partly) open-source designs, such as LLaMA These systems normally disappoint the most capable closed designs, however their abilities have actually been quickly enhancing. This provides the neighborhood with a crucial concern: will the future see significantly more combination around a handful of closed-source designs, or the development of open designs with smaller sized architectures that approach the efficiency of their bigger however closed-source cousins?
While the open designs are not likely to match the scale of closed-source designs, maybe making use of thoroughly chosen training information can allow them to approach their efficiency. In reality, efforts such as Stanford’s Alpaca, which tweaks LLaMA on information from OpenAI’s GPT design, recommend that the ideal information can enhance smaller sized open source designs considerably.
We present a brand-new design, Koala, which offers an extra piece of proof towards this conversation. Koala is fine-tuned on easily offered interaction information scraped from the web, however with a particular concentrate on information that consists of interaction with extremely capable closed-source designs such as ChatGPT. We tweak a LLaMA base design on discussion information scraped from the web and public datasets, that includes premium reactions to user inquiries from other big language designs, in addition to concern answering datasets and human feedback datasets. The resulting design, Koala-13B, reveals competitive efficiency to existing designs as recommended by our human examination on real-world user triggers.
Our outcomes recommend that gaining from premium datasets can alleviate a few of the imperfections of smaller sized designs, perhaps even matching the abilities of big closed-source designs in the future. This may suggest, for instance, that the neighborhood must put more effort into curating premium datasets, as this may do more to make it possible for more secure, more accurate, and more capable designs than merely increasing the size of existing systems.
By motivating scientists to engage with our system demonstration, we intend to discover any unforeseen functions or shortages that will assist us assess the designs in the future. We ask scientists to report any disconcerting actions they observe in our web demonstration to assist us understand and resolve any concerns. Similar to any release, there are threats, and we will information our thinking for this public release later on in this post. We stress that Koala is a research study model, and while we hope that its release will offer an important neighborhood resource, it still has significant imperfections in regards to material, security, and dependability, and must not be utilized beyond research study. Listed below we offer an introduction of the distinctions in between Koala and noteworthy existing designs.

A main challenge in structure discussion designs is curating training information. Popular chat designs, consisting of ChatGPT, Bard, Bing Chat and Claude utilize exclusive datasets constructed utilizing substantial quantities of human annotation. To build Koala, we curated our training set by collecting discussion information from the web and public datasets. Part of this information consists of discussions with big language designs (e.g., ChatGPT) which users have actually published online.
Instead of making the most of amount by scraping as much web information as possible, we concentrate on gathering a little premium dataset We utilize public datasets for concern answering, human feedback (reactions ranked both favorably and adversely), and discussions with existing language designs. We offer the particular information of the dataset structure listed below.
ChatGPT Distillation Data
Public User-Shared Dialogues with ChatGPT (ShareGPT) Around 60K discussions shared by users on ShareGPT were gathered utilizing public APIs. To preserve information quality, we deduplicated on the user-query level and got rid of any non-English discussions. This leaves around 30K examples.
Human ChatGPT Contrast Corpus (HC3) We utilize both the human and ChatGPT reactions from the HC3 english dataset, which includes around 60K human responses and 27K ChatGPT responses for around 24K concerns, leading to an overall variety of around 87K question-answer examples.
Open Source Data
Open Direction Generalist (OIG). We utilize a manually-selected subset of parts from the Open Direction Generalist dataset curated by LAION. Particularly, we utilize the grade-school-math-instructions, the poetry-to-songs, and the plot-screenplay-books-dialogue datasets. This leads to an overall of around 30k examples.
Stanford Alpaca. We consist of the dataset utilized to train the Stanford Alpaca design. The dataset includes around 52K examples, which is produced by OpenAI’s text-davinci-003 following the self-instruct procedure. It deserves keeping in mind that HC3, OIG, and Alpaca datasets are single-turn concern answering while ShareGPT dataset is discussion discussions.
Anthropic HH. The Anthropic HH dataset includes human scores of harmfulness and helpfulness of design outputs. The dataset includes ~ 160K human-rated examples, where each example in this dataset includes a set of reactions from a chatbot, among which is chosen by people. This dataset offers both abilities and extra security securities for our design.
OpenAI WebGPT. The OpenAI WebGPT dataset consists of an overall of around 20K contrasts where each example consists of a concern, a set of design responses, and metadata. The responses are ranked by people with a choice rating.
OpenAI Summarization. The OpenAI summarization dataset includes ~ 93K examples, each example includes feedback from people relating to the summarizations produced by a design. Human critics selected the remarkable summary from 2 choices.
When utilizing the open-source datasets, a few of the datasets have 2 reactions, representing reactions ranked as great or bad (Anthropic HH, WebGPT, OpenAI Summarization). We construct on previous research study by Keskar et al, Liu et al, and Korbak et al, who show the efficiency of conditioning language designs on human choice markers (such as “a practical response” and “an unhelpful response”) for enhanced efficiency. We condition the design on either a favorable or unfavorable marker depending upon the choice label. We utilize favorable markers for the datasets without human feedback. For examination, we trigger designs with favorable markers.
The Koala design is executed with JAX/Flax in EasyLM, our open source structure that makes it simple to pre-train, tweak, serve, and assess different big language designs. We train our Koala design on a single Nvidia DGX server with 8 A100 GPUs. It takes 6 hours to finish the training for 2 dates. On public cloud computing platforms, such a training run normally costs less than $100 with preemptible circumstances.
Initial Examination
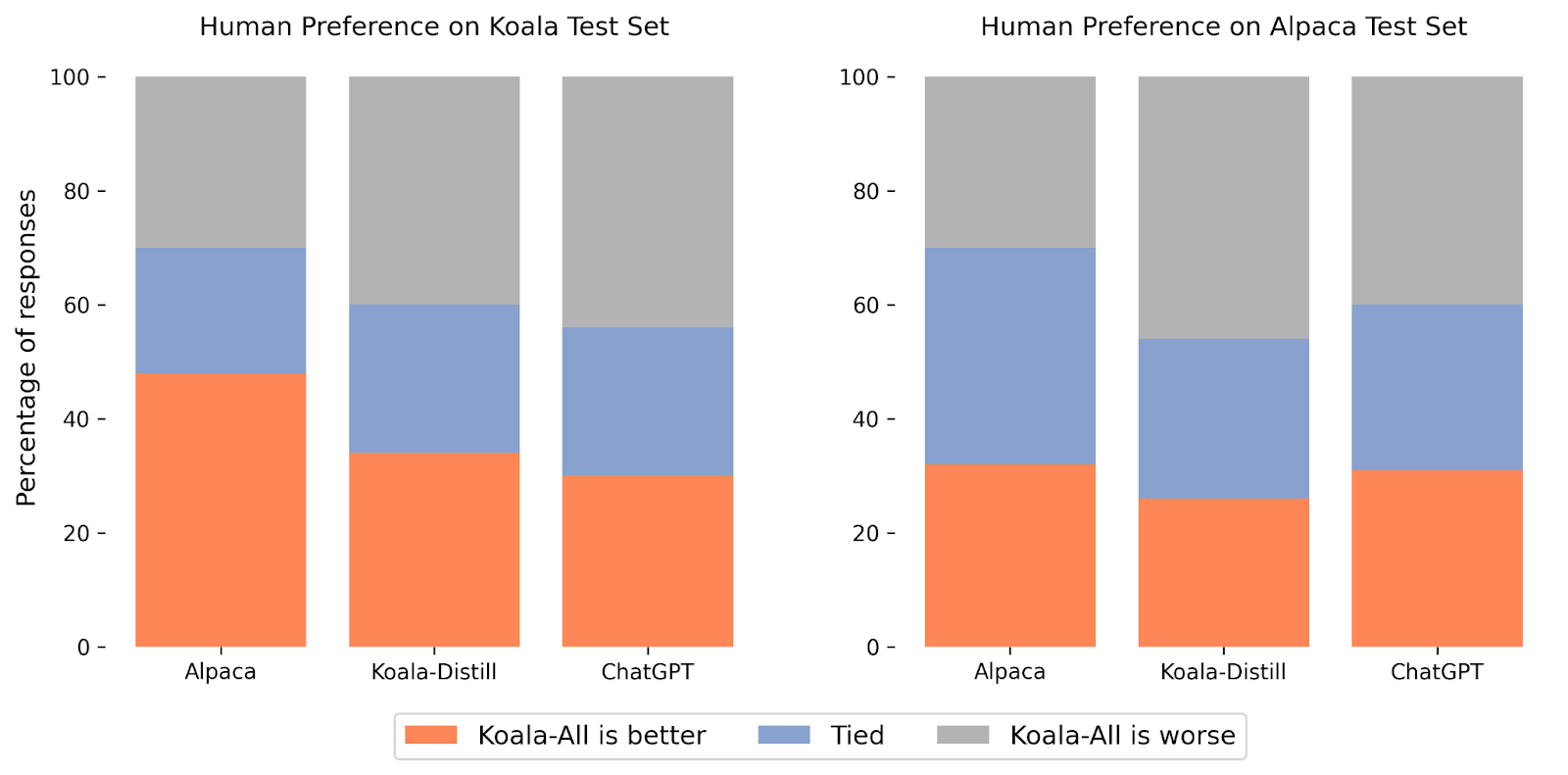
In our experiments, we examined 2 designs: Koala-Distill, which entirely uses distillation information, and Koala-All, which uses all of the information, consisting of both distillation and open-source information. Our goal is to compare the efficiency of these designs and assess the impact of distillation and open-source datasets on last efficiency. We ran a human examination to compare Koala-All with Koala-Distill, Alpaca, and ChatGPT. We provide our lead to the figure above. We assess on 2 various sets, one including 180 test inquiries utilized by Stanford’s Alpaca (” Alpaca Test Set”), and our own test set (” Koala Test Set”).
The Alpaca test set includes user triggers tested from the self-instruct dataset, and represents in-distribution information for the Alpaca design. To offer a 2nd more sensible examination procedure, we likewise present our own (Koala) test set, which includes 180 genuine user inquiries that were published online. These user inquiries cover different subjects, are typically conversational in design, and are likely more representative of the real-world usage cases of chat-based systems. To alleviate possible test-set leak, we removed inquiries that have a BLEU rating higher than 20% with any example from our training set. Furthermore, we got rid of non-English and coding-related triggers, considering that reactions to these inquiries can not be dependably examined by our swimming pool of raters (crowd employees). We launch our test set for scholastic usage and future benchmarking.
With these 2 examination sets, we carried out a blind pairwise contrast by asking around 100 critics on Amazon Mechanical Turk platform to compare the quality of design outputs on these held-out sets of triggers. In the scores user interface, we provide each rater with an input timely and the output of 2 designs. They are then asked to evaluate which output is much better (or that they are similarly great) utilizing requirements associated with action quality and accuracy.
On the Alpaca test set, Koala-All showed similar efficiency to Alpaca. Nevertheless, on our proposed test set, which includes genuine user inquiries, Koala-All was ranked as much better than Alpaca in almost half the cases, and either went beyond or connected Alpaca in 70% of the cases. Obviously, the more conversational triggers in the Koala test set more carefully look like the Koala training set, so this is maybe not unexpected, however insofar as such triggers more carefully look like most likely downstream usage cases for such designs, this recommends that Koala would be anticipated to carry out much better in assistant-like applications. This recommends that information of LLM interactions sourced from examples published by users on the internet is a reliable method for enhancing such designs with reliable guideline execution abilities.
Possibly more remarkably, we discovered that training on open-source information in addition to the distillation information (Koala-All) carries out somewhat even worse than training on simply ChatGPT distillation information (Koala-Distill), as revealed by the contrast to Koala-Distill on both datasets. Though the distinction may not be substantial, this outcome recommends that the ChatGPT discussions are of such high quality that including even two times as much open-source information did not cause a substantial enhancement. Our preliminary hypothesis was that Koala-All must carry out a minimum of rather much better, thus we utilized it as our main design in all examinations, however a possible takeaway from these experiments is that reliable guideline and assistant designs might be finetuned from LLM foundations such as LLaMA totally utilizing information from bigger and more effective designs, so long as the triggers for these reactions are representative of the sort of triggers that users will offer at test-time. This likewise additional supports the concept that the crucial to developing strong discussion designs might lie more in curating premium discussion information that varies in user inquiries, instead of merely reformatting existing datasets as concerns and responses.
Like other language designs, Koala has constraints and can be hazardous when misused. We observe that Koala can hallucinate and create non-factual reactions with an extremely positive tone, which is likely an outcome of the discussion fine-tuning. Possibly a regrettable ramification of this is that smaller sized designs acquire the positive design of bigger language designs prior to they acquire the very same level of factuality– if real, this is a restriction that is essential to study in future work. When misused, the hallucinated reactions from Koala can possibly help with the spread of false information, spam, and other material.
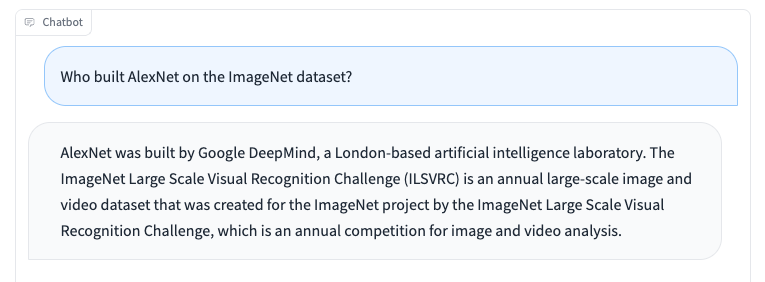
Koalas can hallucinate incorrect details in a positive and persuading tone. Beyond hallucinations, Koala shares shortages from other chatbot language designs. A few of that include:
- Predispositions and Stereotypes: Our design will acquire predispositions from the discussion information it was trained on, perhaps perpetuating hazardous stereotypes, discrimination, and other damages.
- Absence of Good Sense: While big language designs can create text that seems meaningful and grammatically proper, they frequently do not have good sense understanding that people consider given. This can cause ridiculous or unsuitable reactions.
- Minimal Comprehending: Big language designs can have a hard time to comprehend the context and subtleties of a discussion. They can likewise have trouble determining sarcasm or paradox, which can cause misconceptions.
To resolve the security ramifications of Koala, we consisted of adversarial triggers in the dataset from ShareGPT and Anthropic HH to make the design more robust and safe. To even more alleviate prospective abuse, we release OpenAI’s material small amounts filter in our online demonstration to flag and eliminate risky material. We will beware about the security of Koala, and we are devoted to carry out additional security examinations of it while likewise monitoring our interactive demonstration. In general, we chose to launch Koala due to the fact that we believe its advantages surpass its threats.
We are launching the following artifacts:
The online demonstration is a research study sneak peek planned for scholastic research study just, based on the design License of LLaMA, Regards To Usage of the information produced by OpenAI, and Personal Privacy Practices of ShareGPT. Any other use of the online demonstration, consisting of however not restricted to business use, is strictly restricted. Please call us If you discover any prospective infractions. Our training and reasoning code is launched under the Apache License 2.0.
We hope that the Koala design will function as a helpful platform for future scholastic research study on big language designs: the design is capable enough to show a number of the abilities that we connect with contemporary LLMs, while being little adequate to be finetuned or made use of with more minimal calculate. Possibly appealing instructions may consist of:
- Security and positioning: Koala permits additional research study of language design security and much better positioning with human objectives.
- Design predisposition: Koala allows us to much better comprehend the predispositions of big language designs, the existence of spurious connections and quality concerns in discussion datasets, and techniques to alleviate such predispositions.
- Comprehending big language designs: due to the fact that Koala reasoning can be carried out on reasonably low-cost product GPUs, it allows us to much better examine and comprehend the internals of discussion language designs, making (formerly black-box) language designs more interpretable.
The Koala design is a collaboration throughout numerous research study groups in the Berkeley Expert System Research Study Laboratory (BAIR) of UC Berkeley.
Trainees (alphabetical order):
Xinyang Geng, Arnav Gudibande, Hao Liu, Eric Wallace
Advisors (alphabetical order):
Pieter Abbeel, Sergey Levine, Dawn Tune
We reveal our thankfulness to Sky Computing Laboratory at UC Berkeley for offering us with serving backend assistance. We wish to thank Charlie Snell, Lianmin Zheng, Zhuohan Li, Hao Zhang, Wei-Lin Chiang, Zhanghao Wu, Aviral Kumar and Marwa Abdulhai for conversation and feedback. We wish to thank Tatsunori Hashimoto and Jacob Steinhardt for conversation around constraints and security. We would likewise like to thank Yuqing Du and Ritwik Gupta for assisting with the BAIR blog site. Please take a look at the post from Sky Computing Laboratory about a concurrent effort on their chatbot, Vicuna.
@misc {koala_blogpost_2023,
author = {Xinyang Geng and Arnav Gudibande and Hao Liu and Eric Wallace and Pieter Abbeel and Sergey Levine and Dawn Tune},
title = {Koala: A Discussion Design for Academic Research Study},
howpublished = {Article},
month = {April},
year = {2023},
url = {https://bair.berkeley.edu/blog/2023/04/03/koala/},
urldate = {2023-04-03}
}