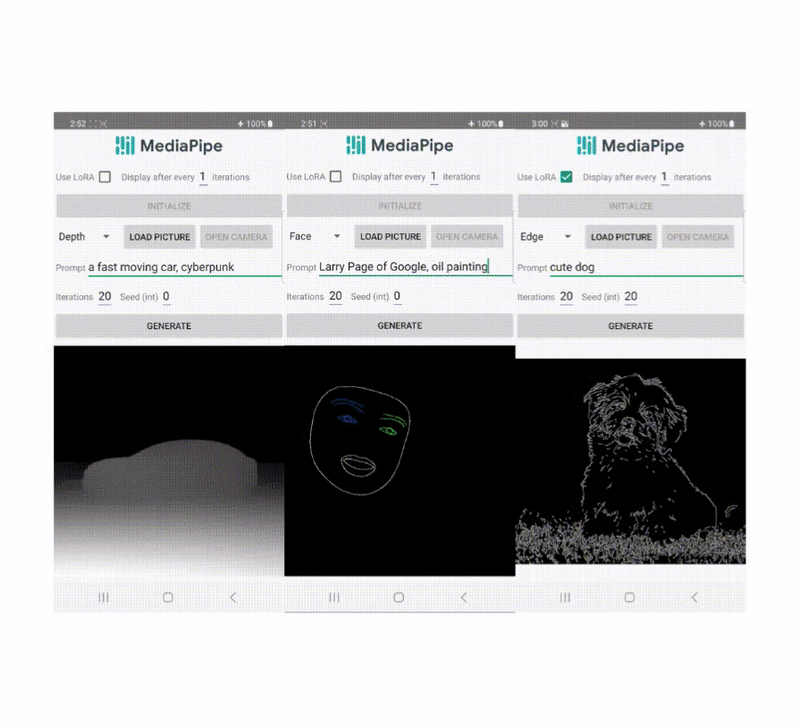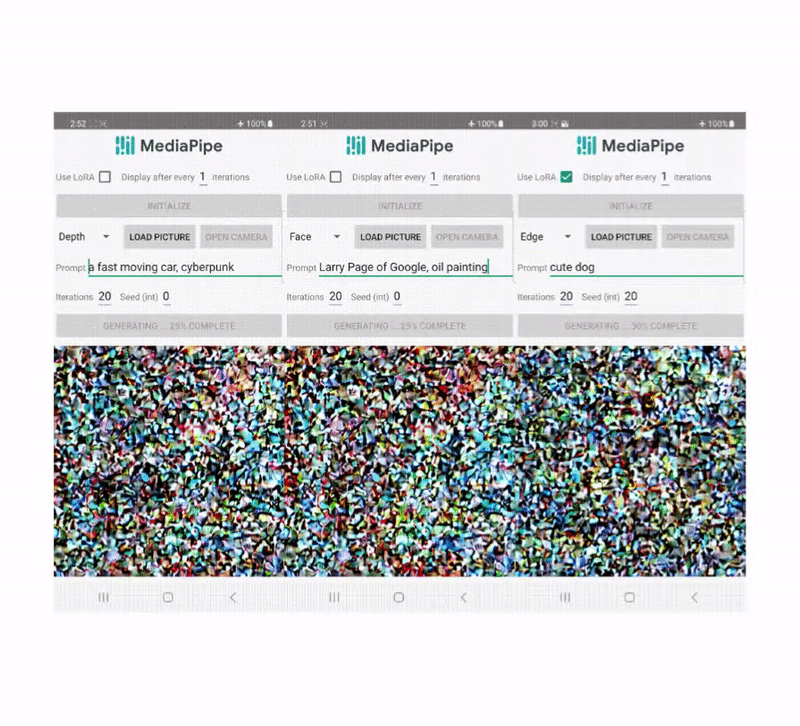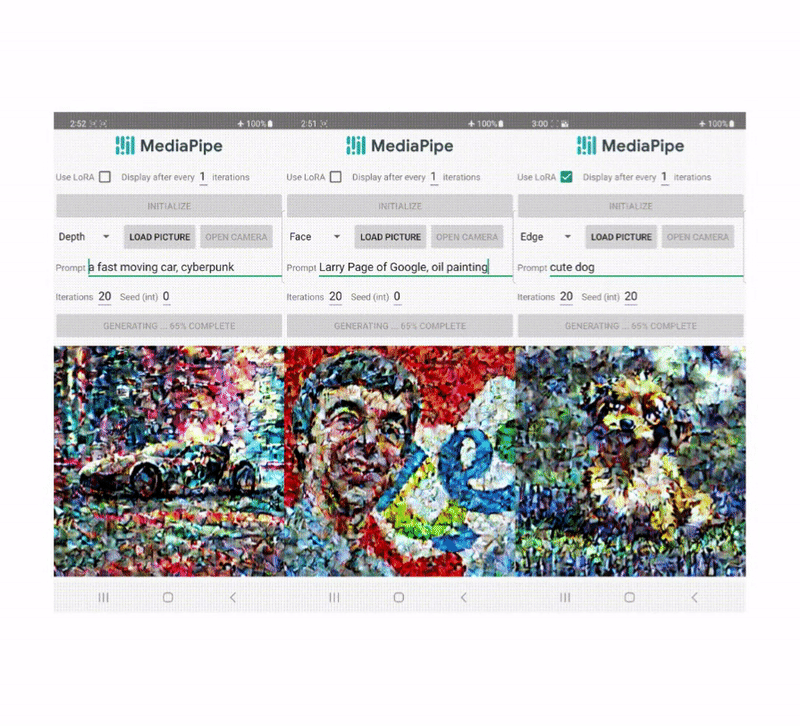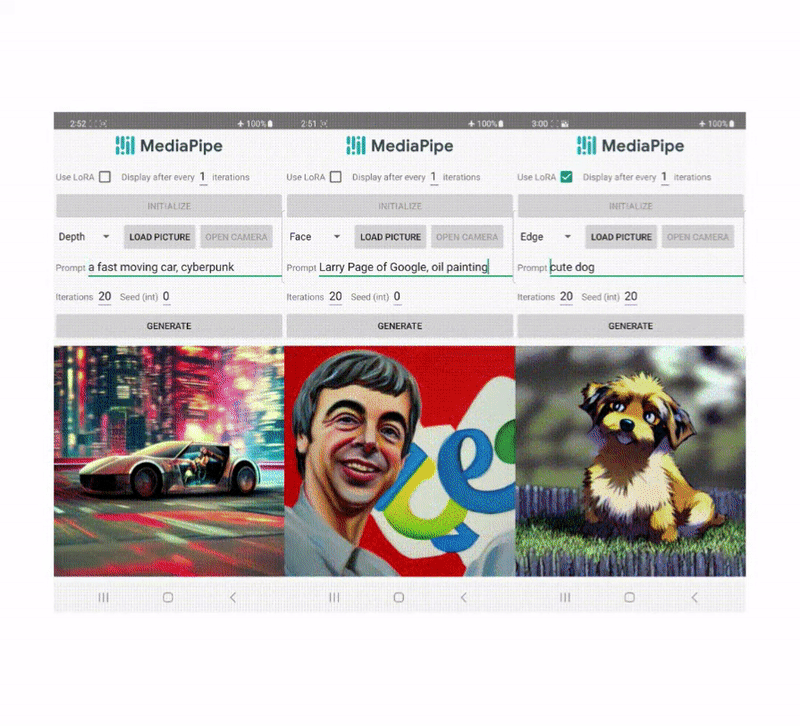
Recently, diffusion designs have actually revealed fantastic success in text-to-image generation, accomplishing high image quality, enhanced reasoning efficiency, and broadening our innovative motivation. However, it is still challenging to effectively manage the generation, specifically with conditions that are tough to explain with text.
Today, we reveal MediaPipe diffusion plugins, which allow manageable text-to-image generation to be run on-device. Broadening upon our previous work on GPU reasoning for on-device big generative designs, we present brand-new low-priced options for manageable text-to-image generation that can be plugged into existing diffusion designs and their Low-Rank Adjustment ( LoRA) versions.
 |
| Text-to-image generation with control plugins running on-device. |
Background
With diffusion designs, image generation is designed as an iterative denoising procedure. Beginning with a sound image, at each action, the diffusion design slowly denoises the image to expose a picture of the target principle. Research study reveals that leveraging language understanding through text triggers can significantly enhance image generation. For text-to-image generation, the text embedding is linked to the design through cross-attention layers. Yet, some details is tough to explain by text triggers, e.g., the position and posture of an item. To resolve this issue, scientists include extra designs into the diffusion to inject control details from a condition image.
Typical methods for regulated text-to-image generation consist of Plug-and-Play, ControlNet, and T2I Adapter Plug-and-Play uses an extensively utilized denoising diffusion implicit design ( DDIM) inversion method that reverses the generation procedure beginning with an input image to obtain a preliminary sound input, and after that uses a copy of the diffusion design (860M specifications for Steady Diffusion 1.5) to encode the condition from an input image. Plug-and-Play extracts spatial functions with self-attention from the copied diffusion, and injects them into the text-to-image diffusion. ControlNet develops a trainable copy of the encoder of a diffusion design, which links through a convolution layer with zero-initialized specifications to encode conditioning details that is communicated to the decoder layers. Nevertheless, as an outcome, the size is big, half that of the diffusion design (430M specifications for Steady Diffusion 1.5). T2I Adapter is a smaller sized network (77M specifications) and attains comparable results in manageable generation. T2I Adapter just takes the condition image as input, and its output is shared throughout all diffusion versions. Yet, the adapter design is not developed for portable gadgets.
The MediaPipe diffusion plugins
To make conditioned generation effective, personalized, and scalable, we develop the MediaPipe diffusion plugin as a different network that is:.
- Plugable: It can be quickly linked to a pre-trained base design.
- Trained from scratch: It does not utilize pre-trained weights from the base design.
- Portable: It runs outside the base design on mobile phones, with minimal expense compared to the base design reasoning.
| Technique | Criterion Size | Plugable | From Scratch | Portable | ||||
| Plug-and-Play. | 860M *. | â. | â. | â. | ||||
| ControlNet. | 430M *. | â. | â. | â. | ||||
| T2I Adapter. | 77M. | â. | â. | â. | ||||
| MediaPipe Plugin. | 6M. | â. | â. | â. |
| Contrast of Plug-and-Play, ControlNet, T2I Adapter, and the MediaPipe diffusion plugin. * The number differs depending upon the details of the diffusion design. |
The MediaPipe diffusion plugin is a portable on-device design for text-to-image generation. It draws out multiscale functions from a conditioning image, which are contributed to the encoder of a diffusion design at matching levels. When linking to a text-to-image diffusion design, the plugin design can offer an additional conditioning signal to the image generation. We develop the plugin network to be a light-weight design with only 6M specifications. It utilizes depth-wise convolutions and inverted traffic jams from MobileNetv2 for quick reasoning on mobile phones.
 |
| Summary of the MediaPipe diffusion design plugin. The plugin is a different network, whose output can be plugged into a pre-trained text-to-image generation design. Functions drawn out by the plugin are used to the associated downsampling layer of the diffusion design (blue). |
Unlike ControlNet, we inject the very same control functions in all diffusion versions. That is, we just run the plugin as soon as for one image generation, which conserves calculation. We show some intermediate outcomes of a diffusion procedure listed below. The control works at every diffusion action and makes it possible for regulated generation even at early actions. More versions enhance the positioning of the image with the text timely and produce more information.
 |
| Illustration of the generation procedure utilizing the MediaPipe diffusion plugin. |
Examples
In this work, we established plugins for a diffusion-based text-to-image generation design with MediaPipe Face Landmark, MediaPipe Holistic Landmark, depth maps, and Canny edge For each job, we pick about 100K images from a web-scale image-text dataset, and calculate control signals utilizing matching MediaPipe options. We utilize improved captions from PaLI for training the plugins.
Face Landmark
The MediaPipe Face Landmarker job calculates 478 landmarks (with attention) of a human face. We utilize the drawing utils in MediaPipe to render a face, consisting of face shape, mouth, eyes, eyebrows, and irises, with various colors. The following table reveals arbitrarily created samples by conditioning on face mesh and triggers. As a contrast, both ControlNet and Plugin can manage text-to-image generation with offered conditions.
 |
| Face-landmark plugin for text-to-image generation, compared to ControlNet. |
Holistic Landmark
MediaPipe Holistic Landmarker job consists of landmarks of body posture, hands, and face mesh. Listed below, we produce numerous elegant images by conditioning on the holistic functions.
 |
| Holistic-landmark plugin for text-to-image generation. |
Depth
 |
| Depth-plugin for text-to-image generation. |
Canny Edge
 |
| Canny-edge plugin for text-to-image generation. |
Examination
We carry out a quantitative research study of the face landmark plugin to show the design’s efficiency. The examination dataset includes 5K human images. We compare the generation quality as determined by the commonly utilized metrics, Fréchet Creation Range (FID) and CLIP ratings. The base design is a pre-trained text-to-image diffusion design. We utilize Steady Diffusion v1.5 here.
As displayed in the following table, both ControlNet and the MediaPipe diffusion plugin produce better sample quality than the base design, in regards to FID and CLIP ratings. Unlike ControlNet, which requires to perform at every diffusion action, the MediaPipe plugin just runs as soon as for each image created. We determined the efficiency of the 3 designs on a server device (with Nvidia V100 GPU) and a smart phone (Galaxy S23). On the server, we run all 3 designs with 50 diffusion actions, and on mobile, we run 20 diffusion actions utilizing the MediaPipe image generation app Compared to ControlNet, the MediaPipe plugin reveals a clear benefit in reasoning performance while protecting the sample quality.
| Design | FID â | CLIP â | Reasoning Time (s) | |||||
| Nvidia V100 | Galaxy S23 | |||||||
| Base. | 10.32. | 0.26. | 5.0. | 11.5. | ||||
| Base + ControlNet. | 6.51. | 0.31. | 7.4 (+48%). | 18.2 (+58.3%). | ||||
| Base + MediaPipe Plugin. | 6.50. | 0.30. | 5.0 (+0.2%). | 11.8 (+2.6%). | ||||
| Quantitative contrast on FID, CLIP, and reasoning time. |
We check the efficiency of the plugin on a wide variety of mobile phones from mid-tier to high-end. We note the outcomes on some representative gadgets in the following table, covering both Android and iOS.
| Gadget | Android | iOS | ||||||||||
| Pixel 4 | Pixel 6 | Pixel 7 | Galaxy S23 | iPhone 12 Pro | iPhone 13 Pro | |||||||
| Time (ms). | 128. | 68. | 50. | 48. | 73. | 63. | ||||||
| Reasoning time (ms) of the plugin on various mobile phones. |
Conclusion
In this work, we provide MediaPipe, a portable plugin for conditioned text-to-image generation. It injects functions drawn out from a condition image to a diffusion design, and subsequently manages the image generation. Portable plugins can be linked to pre-trained diffusion designs working on servers or gadgets. By running text-to-image generation and plugins totally on-device, we allow more versatile applications of generative AI.
Recommendations
We want to thank all employee who added to this work: Raman Sarokin and Juhyun Lee for the GPU reasoning service; Khanh LeViet, Chuo-Ling Chang, Andrei Kulik, and Matthias Grundmann for management. Unique thanks to Jiuqiang Tang, Joe Zou and Lu wang, who made this innovation and all the demonstrations running on-device.